
Dem Konzept der RX.control-Software, genauer der Infrastrukursoftware, liegt ein bestimmtes Architectural Design Pattern (Architekturmuster, Entwurfsmuster) zugrunde, das sich als felderprobt erwiesen hat - siehe Referenzen. Etwas akademisch wird es manchmal ein "System kommunizierender Zustandsautomaten" genannt.
Wie unter Einsatzfelder beschrieben, bezieht sich das Muster auf die Architektur einer verteilten Anwendung aus mehreren Prozessen, die miteinander kommunizieren und Daten austauschen. Das Konzept wird im folgenden Diagramm illustriert. Die Farben zeigen die Schichten aus dem Schichtenmodell an und verdeutlichen, wie die RX.control-Komponenten die Applikation untermauern.
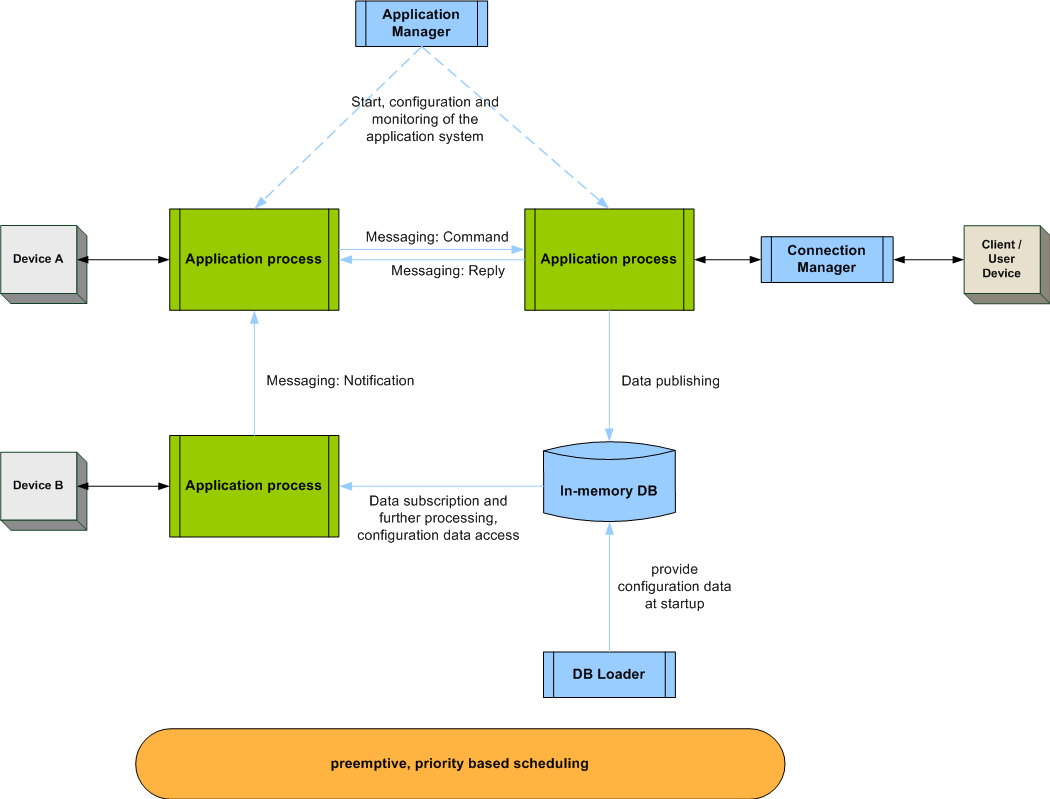
Die wesentlichen Charakteristika einer solchen Architektur sind:
- Ein Applikationsprozess implementiert z.B. die Steuerung eines Gerätes, einen bestimmten Service oder eine Stufe einer Datenverarbeitungskette.
- Mehrere solcher dedizierter Prozesse realisieren so auf modulare, ggf. verteilte Weise die Funktionalität des Gesamtsystems.
- Die interne Logik eines Applikationsprozesses wird durch Ereignisse bestimmt, die als Nachrichten in einer Message Queue eintreffen und entsprechende Handlerfunktionen aufrufen. Eine Zustandsmaschine definiert und verwaltet die Betriebszustände des Prozesses, die durch diese Ereignisse getrieben wird.
- Applikationsprozesse kommunizieren untereinander mit Messages, die Kommandos, Antworten oder Benachrichtigungen darstellen und vom Empfänger als Ereignisse behandelt werden.
- Applikationsprozesse veröffentlichen Daten in einer zentralen In-Memory-Datenbank und lesen daraus Daten anderer Prozesse. Auch die initiale Konfiguration von Prozessen erfolgt auf diesem Weg. Prozesse können sich über Änderungen in der Datenbank benachrichtigen lassen.
- Mit den Konzepten des Messagings und der Datenbank sind die Applikationsprozesse schwach gekoppelt. Der Kommando- und Datenfluss lässt sich so per Konfiguration anpassen ohne ein Neubauen der Applikation zu erfordern.
- Eine zentrale Instanz - der Applikationsmanager - startet und konfiguriert das System der Applikationsprozesse, nachdem zentrale Dienste, wie die In-Memory-Datenbank, die Netzwerkkommunikation und das Logging initialisiert wurden.
- Zur Laufzeit überwacht der Applikationsmanager das System.